数据库学习笔记
MySQL
基础知识
SELECT
语法结构
SELECT select_list
FROM table_name;注意事项
SQL语法不区分大小写,但为了格式化和强调性关键字最好大写。FROM关键字最好另起一行,为了更好阅读和管理。- 在程序端写查询语句时,最好指定要查询的列。说明
ORDER BY
语法结构
SELECT
select_list
FROM
table_name
ORDER BY
column1 [ASC|DESC],
column2 [ASC|DESC],
...;说明
ASC代表升序,DESC代表降序。- 当未指定列的排序时,默认为升序排列
注意事项
- 当
SELECT结果按多个字段排序时,先对第一个字段排序后,再在第一次排序的结果之上排序第二个字段,第一个字段的顺序不会改变。 ORDER BY在SELECT子句之后进行评估,所以可以使用SELECT子句中指定的别名。
WHERE
语法结构
SELECT
select_list
FROM
table_name
WHERE
search_condition;注意事项
WHERE子句可以用在UPDATE,DELETE语句中。WHERE的评估顺序在FROM子句之后SELECT子句之前。OR只要满足第一个条件后,不会在判断第二个条件。- 检查值为
NULL,使用WHERE value IS NULL并不是=。
WHERE 子句中可以使用 AND OR BETWEEN...AND... LIKE IN IS NULL 等操作符。
LIKE使用%匹配任意字符或_一个字符。<>和!=等效,都表示不等于。NULL在数据库中表示数据缺失或未知,和空字符串或 0 不等效。
SELECT DISTINCT
语法结构
SELECT DISTINCT
select_list
FROM
table_name;注意事项
- 使用 DISTINCT 子句时,MySQL 对待 NULL 都是一个值。
- DISTINCT 作用多个列时,会联合查询的内容进行去从。
- 当没有使用联合函数时,使用
GROUP BY和DISTINCT子句的效果相同。不同在于GROUP BY会排序结果集,但是在版本 8.0 及之后没有显示排序GROUP BY子句的结果集时,也是未排序的。
子句执行顺序
FROM -> WHERE -> SELECT-> GROUP BY -> HAVING -> ORDER BY -> LIMIT
操作符
- 进行操作符判断时当第一个条件满足且能得出结论时就不会执行后面的表达式了。
- 操作符优先级:
AND>OR IN操作符先对 value 进行类型评估,然后对列表值进行排序,再二分查找。IN通常用在子查询结果上。LIKE中匹配特殊字符可以使用反斜杠进行转义%\_20%或使用ESCAPE子句LIKE '%$_20%' ESCAPE '$'LIMIT语句限制显示的结果集.LIMIT [offset,] row_countoffset 从0开始。HAVING子句作用为一组行或集合指定过滤条件。如果忽略了GROUP BY那么它的作用和WHERE在SELECT语句中一样了。HAVING子句将过滤条件应用于每组行,而WHERE子句将过滤条件应用于每行。HAVING子句仅在与GROUP BY子句一起使用以生成高级报告的输出时才有用。TINYINT(1)表示boolean类型 0 代表 false, 1 代表 true.AS通常用在表连接中,不能用在WHERE子句中。
Having 子句
Having 用在 SELECT 语句中作为分组查询结果集或聚合函数结果集的过滤条件,它与 WHERE 的区别在于 WHERE 作用于每行,Having 作用于一组。
Group By 子句
当没有使用 Group By 而使用聚合函数时,只会得到一行记录因为聚合函数会统计整个表中的数据。它可以执行分组的别名和排序,标准SQL不允许。当 Group By 多个字段的时候是将具有这几个相同字段的放到一个组中。
ROLLUP 子句
使用在 Group By 中的扩展,它可以在 Group By 的分组上生成多个分组。Group By c1,c2,c3 WITH ROLLUP 优先级 c1 > c2 > c3。
表连接
MySQL 支持4种类型的连接 Inner join Left join Right join Cross join 。join子句用在SELECT 语句的 FROM 子句之后。MySQL 不支持全外连接!
前三种连接需要连接条件,Cross join 表示两个表做一个笛卡尔积。
INNER JOIN 的 ON 条件和 WHERE 条件作用相同,而在将 WHERE 条件移动到左连接或右连接上结果不同。
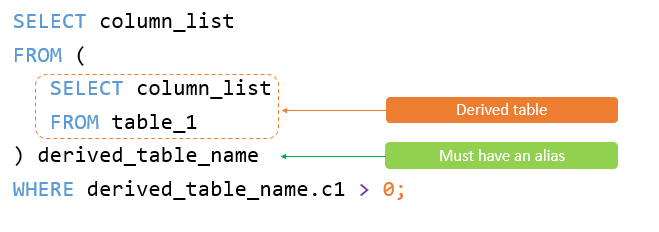
派生表和临时表
在 SELECT 语句中 FROM 子句中使用的子查询叫派生表,它不会生成临时表。
索引
定义
器索引是类似于 B-Tree 的数据结构,它是为了加快表中数据查询速度。创建表的主键时,MySQL 会自动创建特殊的索引 PRIMARY 聚簇索引,它和数据一起存在同一表中,它强制执表的行顺序。
创建索引
通常索引创建是在创建表的时候指定
CREATE TABLE t(
c1 INT PRIMARY KEY,
c2 INT NOT NULL,
c3 INT NOT NULL,
c4 VARCHAR(10),
INDEX (c2,c3)
);通过语句为列创建索引
CREATE INDEX index_name ON table_name (column_list)索引类型
| Storage Engine | Allowed Index Types |
|---|---|
| InnoDB | BTREE |
| MyISAM | BTREE |
| MEMORY/HEAP | HASH, BTREE |
查询索引
查询表中的所有索引
SHOW INDEXES FROM table_name查询表中的指定索引
SHOW INDEXES index_name FROM table_name查询指定数据库中表里的索引
SHOW INDEXES FROM table_name
IN database_name;Or
SHOW INDEXES FROM database_name.table_name;INDEX 和 KEYS 是 INDEXES 的同义词, IN 是 FROM 的同义词,所以下面的语句是一样的结果。
SHOW INDEX IN table_name
FROM database_name;Or
SHOW KEYS FROM table_name IN database_name;删除索引
DROP INDEX index_name ON table_name
[algorithm_option | lock_option];algorithm_option 表示删除算法有 ALGORITHM [=] {DEFAULT|INPLACE|COPY} 三种,MySQL 默认使用 INPLACE 也就是重建一个新表,COPY 是在表将逐行复制到新表中,然后在原始表的副本上执行DROP INDEX。 不允许并发数据操作语句,例如INSERT和UPDATE。
数据类型

MySQL中的数值类型
| Numeric Types | Description |
|---|---|
TINYINT |
A very small integer |
SMALLINT |
A small integer |
MEDIUMINT |
A medium-sized integer |
INT |
A standard integer |
BIGINT |
A large integer |
DECIMAL |
A fixed-point number |
FLOAT |
A single-precision floating point number |
DOUBLE |
A double-precision floating point number |
BIT |
A bit field |
MySQL中的布尔类型
- 在 MySQL 中没有布尔类型而使用最小整数类型 TINYINT(1) 来代替
MySQL中的字符串类型
- string 可以保存任意内容,从纯文本到二进制数据。如图片,文件。
- 字符串还可以基于使用 LIKE 操作符,正则表达式,全文搜索的比较和搜索。
- 二进制字符串就是字节序列
CHAR |
A fixed-length nonbinary (character) string |
|---|---|
VARCHAR |
A variable-length non-binary string |
BINARY |
A fixed-length binary string |
VARBINARY |
A variable-length binary string |
TINYBLOB |
A very small BLOB (binary large object) |
BLOB |
A small BLOB |
MEDIUMBLOB |
A medium-sized BLOB |
LONGBLOB |
A large BLOB |
TINYTEXT |
A very small non-binary string |
TEXT |
A small non-binary string |
MEDIUMTEXT |
A medium-sized non-binary string |
LONGTEXT |
A large non-binary string |
ENUM |
An enumeration; each column value may be assigned one enumeration member |
SET |
A set; each column value may be assigned zero or more SET members |
MySQL中的日期和时间类型
| Date and Time Types | Description |
|---|---|
DATE |
A date value in CCYY-MM-DD format |
TIME |
A time value in hh:mm:ss format |
DATETIME |
A date and time value inCCYY-MM-DD hh:mm:ssformat |
TIMESTAMP |
A timestamp value in CCYY-MM-DD hh:mm:ss format |
YEAR |
A year value in CCYY or YYformat |
- timestamp 数据类型是用来追踪每行数据改变时间
MySQL中的空间数据类型(了解)
| Spatial Data Types | Description |
|---|---|
GEOMETRY |
A spatial value of any type |
POINT |
A point (a pair of X-Y coordinates) |
LINESTRING |
A curve (one or more POINTvalues) |
POLYGON |
A polygon |
GEOMETRYCOLLECTION |
A collection of GEOMETRYvalues |
MULTILINESTRING |
A collection of LINESTRINGvalues |
MULTIPOINT |
A collection of POINTvalues |
MULTIPOLYGON |
A collection of POLYGONvalues |
JSON 数据类型
从版本 5.7.8 开始,加入了 JSON 类型。
创建数据表
建表语法
CREATE TABLE [IF NOT EXISTS] table_name(
column_1_definition,
column_2_definition,
...,
table_constraints
) ENGINE=storage_engine;说明:
- 表名在数据库中必须唯一
- 表列名通过逗号分割
- 存储引擎是可选的,默认为 InnoDB 。(从 MySQL 5.5 版本及之后。特性:ACID transaction,referential integrity, and crash recovery 等 )
数据列语法
column_name data_type(length) [NOT NULL] [DEFAULT value] [AUTO_INCREMENT] column_constraint;- 每个列名都有特定的数据类型和大小。如 VARCHAR(255)
- NOT NULL 约束限制该列不能为 NULL ,除此之外还有 CHECK 和 UNIQUE 约束。
- DEFAULT 为列指定默认值
- AUTO_INCREMENT 当插入一行时,该字段标记的会自动增长,并且每个表只有一个该字段,一般是主键。
除了数据列约束之外还可以包含表约束如:UNIQUE,CHECK,PRIMARY KEY,FOREIGN KEY。
PRIMARY KEY (col1,col2,...)建表语句示例:
CREATE TABLE IF NOT EXISTS tasks (
task_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
start_date DATE,
due_date DATE,
status TINYINT NOT NULL,
priority TINYINT NOT NULL,
description TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=INNODB;建表成功后可以使用 DESCRIBE table_name; 查看表结构
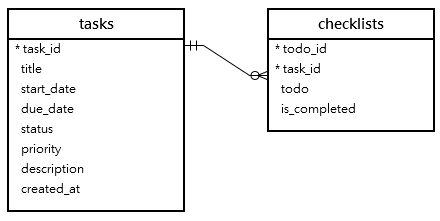
创建拥有外键的数据表:
CREATE TABLE IF NOT EXISTS checklists (
todo_id INT AUTO_INCREMENT,
task_id INT,
todo VARCHAR(255) NOT NULL,
is_completed BOOLEAN NOT NULL DEFAULT FALSE,
PRIMARY KEY (todo_id , task_id),
FOREIGN KEY (task_id)
REFERENCES tasks (task_id)
ON UPDATE RESTRICT ON DELETE CASCADE
);两张表之间的关系:
函数
COUNT
它为集合函数,存在三种形式:COUNT(*), COUNT(expression), COUNT(DISTINCT expression)
- COUNT(*) 返回 SELECT 查询到的结果集数量,包括重复,不为空和空的行
- COUNT(expression) 返回不为空的结果集数量
- COUNT(DISTINCT expression) 返回不为空且不重复的结果集数量



